在当今数字化时代,高并发与海量数据处理已成为互联网服务的关键挑战之一。无论是电商平台、社交应用还是金融系统,都需要应对大量用户同时访问和庞大的数据存储需求。本文将探讨如何设计高效、可扩展的服务来处理高并发和海量数据场景,并分享一些实用的技术策略。
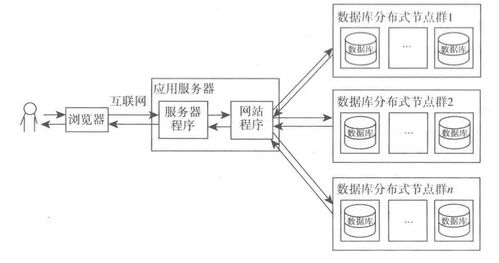
高并发处理的核心在于优化系统架构。采用分布式系统设计,如微服务架构,可以将业务逻辑拆分成多个独立的服务模块,每个模块负责特定功能,从而降低单点故障风险并提升系统的并发处理能力。同时,利用负载均衡器(如Nginx或HAProxy)将请求分发到多个服务器节点,确保资源均衡利用,避免单台服务器过载。引入缓存机制(如Redis或Memcached)可以显著减少数据库的访问压力,通过存储热点数据在内存中,加速响应时间。
海量数据处理需要高效的存储和计算方案。对于数据存储,推荐使用分布式数据库(如Cassandra或HBase)或云存储服务(如AWS S3),这些技术能够水平扩展,支持PB级数据的存储和快速查询。同时,通过数据分区和索引优化,可以提高查询效率并减少I/O瓶颈。在计算层面,采用大数据处理框架(如Apache Spark或Hadoop)能够并行处理海量数据,实现实时或批处理分析。例如,使用Spark Streaming可以处理实时数据流,而Hadoop MapReduce则适合离线分析任务。
监控和容错机制是确保服务稳定性的关键。实施实时监控工具(如Prometheus或Grafana)来跟踪系统性能指标,如CPU使用率、内存占用和请求延迟,以便及时发现并解决瓶颈。同时,设计容错策略,包括数据备份、故障自动恢复和降级机制,当部分组件失效时,系统仍能继续运行。例如,通过数据库主从复制和分布式事务管理,确保数据一致性和可用性。
实际应用中,建议结合具体业务场景进行优化。例如,对于电商平台,可以采用异步处理来处理订单高峰,而社交应用则需优化消息队列(如Kafka)来管理用户互动数据。通过持续测试和性能调优,如压力测试和A/B测试,可以确保系统在高负载下保持稳定。
高并发与海量数据处理的设计服务需要综合运用分布式架构、缓存技术、大数据工具和监控策略。通过合理规划和实现,企业可以构建出高效、可扩展的系统,应对日益增长的用户和数据需求,提升用户体验和业务竞争力。