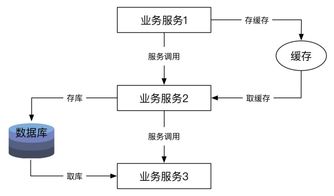
在微服务架构中,数据处理服务作为关键组成部分,承担着数据存储、处理和交互的核心职责。本文将从核心要点和实现原理两个方面,探讨微服务架构下数据处理服务的设计与实现。
一、核心要点
- 服务解耦与独立数据管理:每个微服务应拥有独立的数据存储,避免直接共享数据库,通过API进行数据交互,确保服务间的松耦合。
- 数据一致性保障:在分布式环境中,采用最终一致性策略,结合事件驱动架构(如事件溯源和CQRS模式)来管理数据变更。
- 可扩展性与性能优化:通过水平扩展和分片技术处理海量数据,利用缓存(如Redis)和异步处理提升性能。
- 安全与合规性:实施数据加密、访问控制和审计日志,确保数据处理符合隐私法规(如GDPR)。
二、实现原理
- 数据分片与存储:采用分库分表策略,将数据分散到多个数据库实例,例如使用MySQL分片或NoSQL数据库(如MongoDB)以支持灵活的数据模型。
- 事件驱动架构:通过消息队列(如Kafka或RabbitMQ)实现服务间数据同步,当数据变更时发布事件,其他服务订阅并更新自身状态。
- API网关与数据聚合:利用API网关统一处理数据请求,聚合多个微服务的数据返回给客户端,减少网络开销。
- 容错与监控:引入断路器模式(如Hystrix)和健康检查,结合分布式追踪工具(如Zipkin)监控数据流,确保服务可靠性。
微服务架构下的数据处理服务需在解耦、一致性和可扩展性间取得平衡,通过现代技术栈实现高效、安全的数据操作。